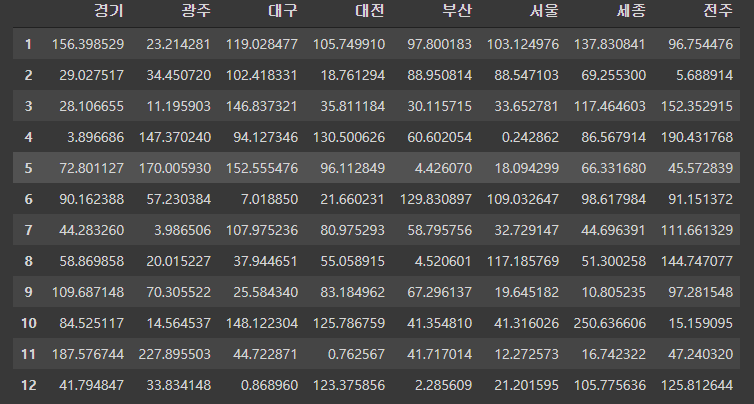
df2d.loc[:, '평균'] = df2d.iloc[:, :8].mean(axis=1)위의 데이터중 모든 열의 7행까지 가로방향의 평균을 구한다.
df2d.sort_values(by=["평균"], ascending=True)평균 값을 기준으로 ascending을 이용하여 오름차순으로 바꾼다.
순위 구하기
- first : DataFrame에 같은 값이 존재하는 경우 저장되어 있는 순서대로 순위를 지정 (값 : 100, 85, 85, 70 ==> 순위 : 1, 2, 3, 4)
- 주의 : first 방법은 숫자 타입만 가능, numeric_only=True도 같이 설정해야 함
- min : 중복 값이 있는 만큼 순위를 건너뛰고 표시 (값 : 100, 85, 85, 70 ==> 순위 : 1, 2, 2, 4)
- max : (값 : 100, 85, 85, 70 ==> 순위 : 1, 3, 3, 4)
r = df2d['평균'].rank(method='min', ascending=False).astype('int32')
df2d.loc[:, '순위'] = r평균을 기준으로 순위를 매긴다.
순위라는 컬럼을 생성하고 모든 행에 적용한다.
합계와 평균 구하기
df2d.loc[:, '월별합계'] = df2d.sum(axis=1)imsi = df2d.iloc[:, :8]
df2d.loc[:, '월별평균']=imsi.mean(axis=1)다음과 같이 합계와 평균을 구할 수 있다.
df2d.mean(axis=1, skipna=False) # NaN을 제외하지 않음skipna를 통해 NaN을 제외하거나 제외하지 않을 수 있다.
요약정보
- count : NaN 값을 제외한 값의 개수를 반환
- describe : Series나 DataFrame의 각 칼럼에 대한 요약 통계를 계산
- min, max : 최솟값과 최댓값을 계산
- argmin, argmax : 각각 최솟값과 최댓값을 가지고 있는 색인의 위치를 정수로 반환
- idmin, idmax : 각각 최솟값과 최댓값을 가지고 있는 색인의 값을 반환
- quantile : 0부터 1까지의 분위수를 계산
- mean : 평균 계산
- median : 중앙값을 계산
- mad : 평균값에서 평균 절대편차를 계산
- prod : 모든 값의 곱을 계산
- var : 표본 분산 값을 계산
- std : 표본 표준편차 값을 계산
- cumsum : 누적합을 계산
- cumprod : 누적곱을 계산
- diff : 1차 산술차를 계산, 시계열 데이터 처리 시 유용
상관관계와 공분산
공분산과 상관계수
공분산은 두 변수간의 단위로 인한 모호한 크기량을 갖고 있는데, 이를 표준화한 것이 '상관계수'이다.
상관관계
- 두 쌍의 인자(X, Y)가 필요
- X가 증감할 때 Y가 얼마나 증감하는가를 나타내는 관계
- -1과 1 사이의 상관계수를 통해 함께 늘어나는지 아니면 반대로 줄어드는지를 설명할 수 있음
- -1과 1에 가까울수록 상관성이 강하고, 0에 가까울수록 상관성이 약함
import numpy as np
import pandas as pd
import pandas_datareader.data as web
all_data = {ticker : web.get_data_yahoo(ticker) for ticker in ['AAPL', 'IBM', 'MSFT', 'GOOG']}
price = pd.DataFrame({ticker : data['Adj Close'] for ticker, data in all_data.items()})
returns= price.pct_change() # (퍼센트 변화율 계산)야후에서 제공하는 기업 코드로 주가와 시가총액을 알 수 있다.
# 4개 회사의 주식 수익율 사이의 피어슨 상관분석
returns.corr(method='pearson')

이 회사 간의 상관관계를 분석한다.
예를 들어 apple과 IBM 사이의 관계는 큰 영향을 가지고 있지 않다고 볼 수 있다.
returns['MSFT'].cov(returns['IBM'])다음과 같이 두 회사 간의 분석을 볼 수 있다.
삼성과 엘지의 주가 상관관계 분석
import numpy as np
import pandas as pd
import pandas_datareader.data as web
import matplotlib.pyplot as plt
samsungEI=web.get_data_yahoo('005930.KS', start='2017-01-01', end='2020-10-22')
lgEI=web.get_data_yahoo('066570.KS', start='2017-01-01', end='2020-10-22')
samsungEI

삼성과 엘지의 주가 데이터를 가져옵니다.
import matplotlib.pyplot as plt
plt.title('Samsung & LG')
plt.plot(samsungEI.loc[:,'Close'], label='samsung')
plt.plot(lgEI.loc[:, 'Close'], label='lg')
plt.legend()
plt.show()
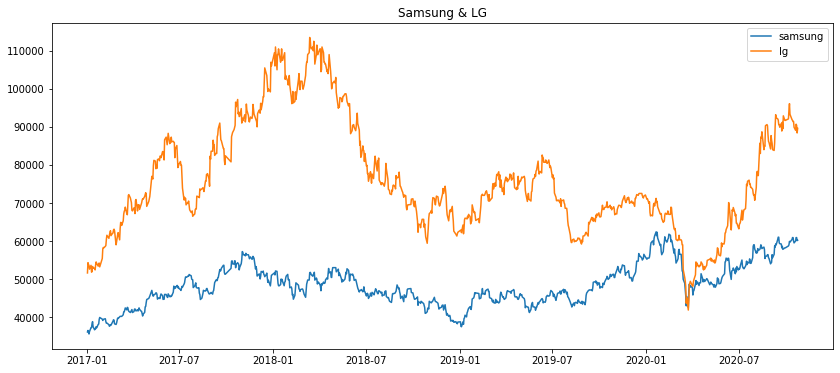
비교하기 쉽게 시각화하여 나타냈습니다.
samsungEI['Close'].cov(lgEI['Close'])

다음과 같은 수치가 나옵니다.
두 기업간의 관계가 낮은 것을 확인할 수 있었습니다.
'빅데이터전문가양성과정' 카테고리의 다른 글
| 머신러닝을 이용한 붓꽃 품종 분류 (0) | 2020.11.23 |
|---|---|
| 공공 데이터 활용 (0) | 2020.11.09 |
| 데이터 분석 (6일차) (0) | 2020.10.22 |
| 데이터 선택 & 슬라이싱 (6일차) (0) | 2020.10.22 |
| 데이터 분석 (5일차) (0) | 2020.10.19 |



